音声¶
コンピュータやロボットが話せれば、より「人間」らしくなるでしょう。
グラフィカルユーザーインターフェイス(GUI)を通してコンピュータで何をするかを学ぶことが多いと思います。BBC micro:bit の場合、GUI は 5×5 の LED マトリックスであり、望まれる多くのことを捨てています。
micro:bit を話せるようにすることは、楽しく、効率的で、有用な方法で情報を表現する方法の1つです。この目的のために、私たちは、1980 年代初めのシンセサイザーのリバースエンジニアリングバージョンに基づく簡単な音声合成装置を統合しましたサウンドは "all humans must die" みたいな感じでとてもキュートです(訳注: この章は、イギリスのTVシリーズ「Doctor Who」を知らないと分からないネタばかりです)。
以上を念頭に置いて、音声シンセサイザを使っていくことにしましょう ...
DALEK の詩¶

DALEK が詩、特にリメリック(滑稽五行詩)を楽しむことはちょっと知られています。DALEK は厳格な AABBA 形式の弱強格韻脚でワイルドになります。誰が考えたのでしょうか?
(実際には、以降で学ぶように、DALEK がリメリックを好きなのはドクターの仕業であり、ダブロス博士の悩みの種です)
いずれにしても、必要に応じて DALEK の詩のリサイタルを作成する予定です。
何か言わせてみる¶
デバイスが話せるようにする前に、以下のようにスピーカーを接続する必要があります:
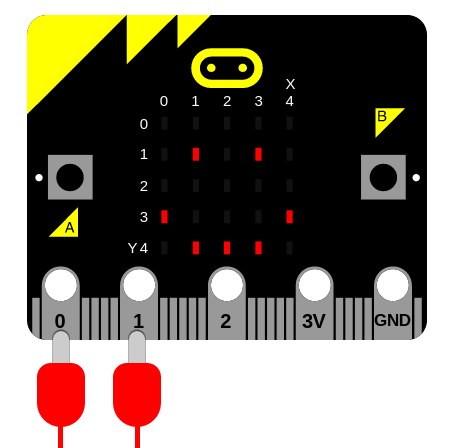
デバイスに話させる最も簡単な方法は、次のように speech モジュールをインポートして、 say 関数を使うことです:
import speech
speech.say("Hello, World")
これでもキュートですが、DALEK のレベルとしては十分でないので、音声合成装置が音声を生成するために使ういくつかのパラメータを変更する必要があります。音声シンセサイザは、この点で非常に強力です。なぜなら、4つのパラメータを変更できるからです:
pitch- 音声の高低s (0 = 高, 255 = Barry White)speed- デバイスが話す速度 (0 = impossible, 255 = bedtime story)mouth- 音声の発音の不明瞭または明瞭の程度 (0 = 腹話術師の人形, 255 = Foghorn Leghorn)throat- 声の調子のリラックスまたは緊張の程度 (0 = falling apart, 255 = totally chilled)
まとめると、これらのパラメータは音の質を制御します。正直言って、望む声の音を得る最良の方法は、実験を繰り返して調整することです。
設定を調整するには、それらを say 関数の引数として渡します。詳細は speech モジュールの API ドキュメンテーションを参照してください。
何回かの実験の後、以下でかなり DALEK 風の音声になりました。
speech.say("I am a DALEK - EXTERMINATE", speed=120, pitch=100, throat=100, mouth=200)
詩オンデマンド(Poetry on Demand)¶
サイボーグである DALEK はロボットの能力を使って詩を作っています。彼らが使うアルゴリズムは Python で次のように書かれています:
# DALEK の詩の自動作成プログラム(著者:ドクター)
import speech
import random
from microbit import sleep
# テンプレートに挿入する断片をランダムに選びます
location = random.choice(["brent", "trent", "kent", "tashkent"])
action = random.choice(["wrapped up", "covered", "sang to", "played games with"])
obj = random.choice(["head", "hand", "dog", "foot"])
prop = random.choice(["in a tent", "with cement", "with some scent",
"that was bent"])
result = random.choice(["it ran off", "it glowed", "it blew up",
"it turned blue"])
attitude = random.choice(["in the park", "like a shark", "for a lark",
"with a bark"])
conclusion = random.choice(["where it went", "its intent", "why it went",
"what it meant"])
# 詩のテンプレート。名前をつけた断片で {} を置き換えます
poem = [
"there was a young man from {}".format(location),
"who {} his {} {}".format(action, obj, prop),
"one night after dark",
"{} {}".format(result, attitude),
"and he never worked out {}".format(conclusion),
"EXTERMINATE",
]
# ループで詩の各行を先頭から見て行き、speech モジュールを使って暗唱します
for line in poem:
speech.say(line, speed=120, pitch=100, throat=100, mouth=200)
sleep(500)
コメントが示すように、デザインは非常にシンプルです:
- 予め定義された言葉のリストから、ランダムに名前つき断片(location、prop、attitudeなど)が生成されます。
random.choiceを使って、リストから単一の項目を選んでいることに注目してください。 - 詩のテンプレートは、その中に「穴」(
{}で表現)のある節のリストとして定義されています。この穴にformatメソッドを使って名前つき断片を埋めます。 - 最後に、Python は、埋め込まれた詩の節のリストの各項目をループして
speech.sayを使って DALEK の声で詩を暗唱します。DALEK でも息をする必要があるので、500 ミリ秒の休止を各行の間に挿入しています。
興味深いことに、当初の詩の関連ルーチンはダブロス博士によって FORTRAN (すべて英大文字でタイプする DALEK の標準言語)で書かれました。しかし、ダブロス博士の 単体テスト パスと デプロイパイプライン の間のポイントにドクターが正確に時を戻して、その瞬間、MicroPython インタプリタを DALEK のオペレーティングシステムに入れ、上記のコードを長い隠される イスターエッグ または リックロール のようなものとして、DALEK のメモリバンクに入れることができました。
音素¶
場合によっては say 関数が英語の単語から正しい音に正確に変換されないことがあります。出力をきめ細かく制御するには、言語の音の最小単位である音素を使用します。
音素を使用する利点は、綴り方を知る必要がないことです。むしろ、それを音声学的に綴るためには、言葉の使い方を知る必要があります。
音声シンセサイザーが理解している音素の全リストは、speech の API ドキュメンテーションにあります。あるいは、英語の単語を translate 関数に渡すことで、時間を節約できます。この関数は、オーディオを生成するために使う音素の近似を最初に生成して返します。この結果は、(もっと自然に聞こえるように)精度、屈曲、強調を手で編集して改善できます。
音素出力には次のように pronounce 関数を使います。
speech.pronounce("/HEH5EH4EH3EH2EH2EH3EH4EH5EHLP.")
ドクターのコードを音素を使って改善してみてください。
micro:bit の歌を歌う¶
pitch 設定の変更と sing 関数の呼出しによって、デバイスを歌えるようにできます(ただし、Eurovision で勝てるとは限りません)。(訳注: Eurovision は欧州放送連合の音楽コンテストです)
pitch 番号から音符へのマッピングを以下に示します。

次のように、 sing 関数には音素と pitch を入力する必要があります。
speech.sing("#115DOWWWW")
歌う pitch の設定として、音素の前にハッシュ(#)で前置した値があることに注目してください。新しい pitch 設定があるまで、pitch は後続の音素に対して同じままとなります。
次の例は、3つの関数(say, pronounce, sing)を使った音声の生成方法を示しています。
"""
speech.py
~~~~~~~~
micro:bit に何かを言わせたり、発音させたり、歌わせたりするための簡単な
speech の利用例です。
この例では P0 と GND に接続されたスピーカー/ブザー/ヘッドフォン、
またはスピーカー内蔵の最新の micro:bit デバイスが必要です。
"""
import speech
from microbit import sleep
# say メソッドは英語から音素への変換を試みます。
speech.say("I can sing!")
sleep(1000)
speech.say("Listen to me!")
sleep(1000)
# throat をクリーンにするには音素を使う必要があります。
# pitch と speed を変更することでも適切な効果が得られます。
speech.pronounce("AEAE/HAEMM", pitch=200, speed=100) # えへん
sleep(1000)
# 歌わせるには各音節ごとに音階の音素が必要です。
solfa = [
"#115DOWWWWWW", # ド
"#103REYYYYYY", # レ
"#94MIYYYYYY", # ミ
"#88FAOAOAOAOR", # ファ
"#78SOHWWWWW", # ソ
"#70LAOAOAOAOR", # ラ
"#62TIYYYYYY", # シ
"#58DOWWWWWW", # ド
]
# 音階が順に高くなっていくよう歌わせます。
song = ''.join(solfa)
speech.sing(song, speed=100)
# 音節のリストの順番を逆にします。
solfa.reverse()
song = ''.join(solfa)
# 音階が順に低くなっていくよう歌わせます。
speech.sing(song, speed=100)